 The Problem Nobody Wants to Talk About
The Problem Nobody Wants to Talk About
Every AI governance conversation eventually hits the same wall: data. You can build the most sophisticated risk management framework, implement every control in ISO 42001, and comply with every article of the EU AI Act — but if the data feeding your AI systems is incomplete, biased, poorly documented, or improperly sourced, none of it matters. The outputs will be unreliable. The decisions will be flawed. And the governance program will be paper-thin.
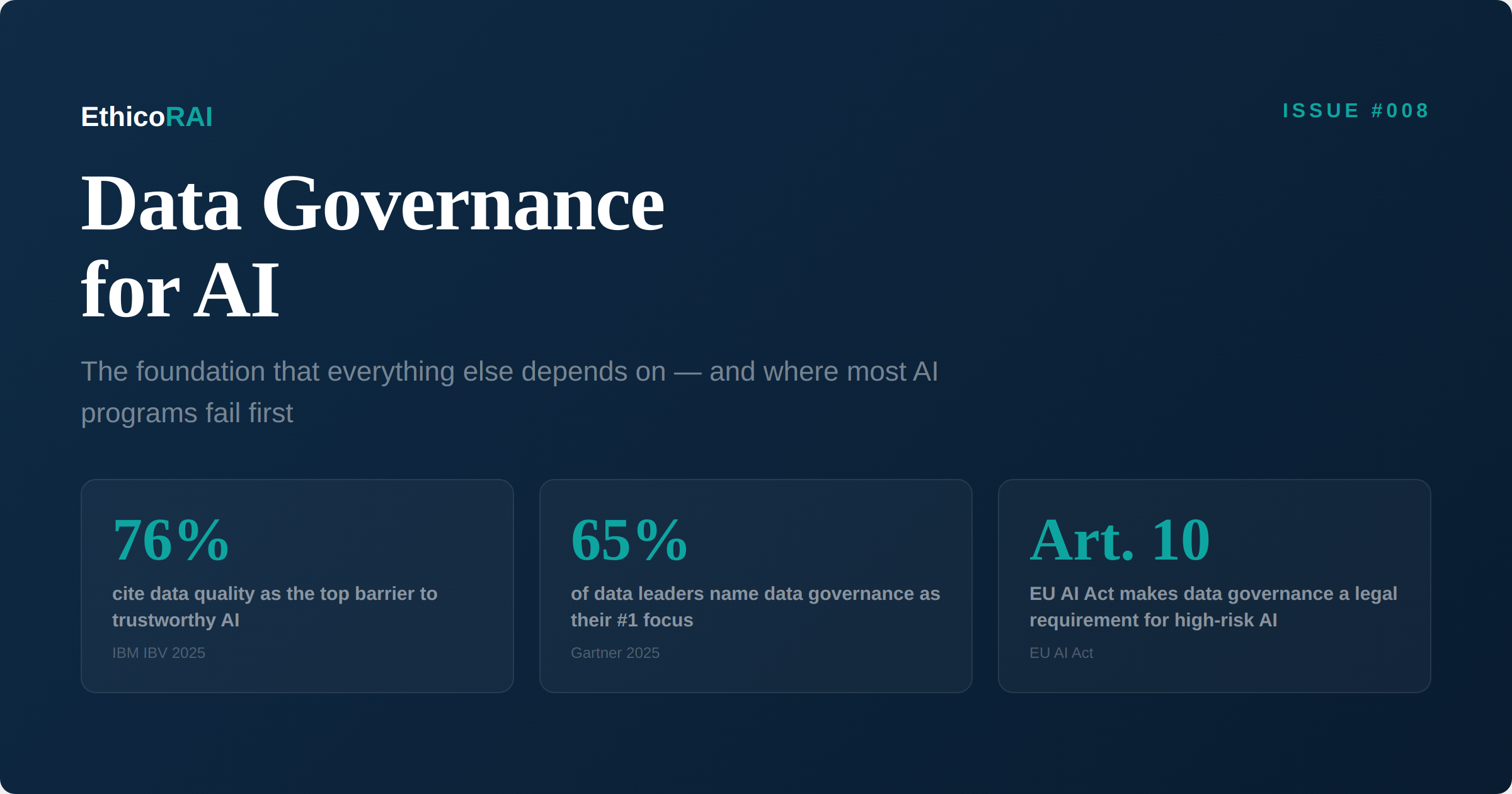
The industry data confirms this. The IBM Institute for Business Value found that 76% of organizations cite poor data quality and governance as the top barrier to trustworthy AI. At a recent Gartner conference, 65% of data leaders named data governance as their number one focus. And yet, when you look at how organizations actually invest in AI, the pattern is familiar: the budget goes to models and compute, while data governance gets the leftovers.
This issue makes the case that data governance isn't a supporting function for AI — it is the foundation. Get it right, and everything else becomes easier: risk management, compliance, fairness, transparency, and performance. Get it wrong, and no amount of governance process can compensate.
What AI Data Governance Actually Means
Traditional data governance — the kind that existed before AI — focuses primarily on accuracy, storage, access control, and regulatory compliance for structured data. AI data governance requires all of that, plus several dimensions that are unique to machine learning and generative AI systems.
We organize these into five pillars:
 Pillar 1: Quality. AI systems are uniquely sensitive to data quality issues. A traditional reporting system might produce a slightly incorrect figure if 2% of input records have errors. An AI model trained on that same data may learn the errors as patterns and amplify them across every prediction it makes. Quality for AI data means accuracy (is the data correct?), completeness (are there gaps that could skew the model?), consistency (does the same entity have the same representation across datasets?), and timeliness (is the data current enough for the model's purpose?).
Pillar 1: Quality. AI systems are uniquely sensitive to data quality issues. A traditional reporting system might produce a slightly incorrect figure if 2% of input records have errors. An AI model trained on that same data may learn the errors as patterns and amplify them across every prediction it makes. Quality for AI data means accuracy (is the data correct?), completeness (are there gaps that could skew the model?), consistency (does the same entity have the same representation across datasets?), and timeliness (is the data current enough for the model's purpose?).
Article 10 of the EU AI Act makes this explicit: training, validation, and testing datasets for high-risk AI systems must meet quality criteria that are appropriate for the intended purpose of the system. This is not a suggestion — it is a legal requirement that will be enforced from August 2026.
Pillar 2: Lineage. Data lineage means being able to trace any piece of data from its original source, through every transformation it undergoes, to its use as input to an AI model. This is essential for three reasons: explainability (when an AI system produces an output, you need to be able to explain what data informed it), debugging (when something goes wrong, you need to trace back to where the data became problematic), and compliance (both ISO 42001 and the EU AI Act require documentation of data sources and processing).
For generative AI systems, lineage becomes even more complex. When a large language model generates a response, the lineage extends back through its training data — potentially billions of documents. Organizations using retrieval-augmented generation (RAG) systems have a more tractable lineage challenge, since they can trace which documents were retrieved and used to inform each response.
Pillar 3: Privacy. AI systems often process personal data at scale, creating privacy risks that compound traditional data protection challenges. The key issues include lawful basis for processing (do you have a valid legal ground to use this data for AI training or inference?), data minimization (are you using only the data necessary for the AI system's purpose?), purpose limitation (if data was collected for one purpose, can you legally use it to train an AI model?), and cross-border transfers (if your AI model was trained on data from EU residents, does the training infrastructure comply with GDPR transfer requirements?).
The intersection of AI governance and privacy governance is one of the most important themes in the field. The IAPP's 2025 research found that organizations where AI governance is led by the privacy function were significantly more confident in their ability to comply with the EU AI Act — precisely because privacy teams bring experience in navigating these data protection complexities.
Pillar 4: Bias. Bias in AI systems almost always originates in data. Historical hiring data reflects past discrimination. Medical datasets underrepresent minority populations. Financial data embeds socioeconomic disparities. If you train an AI system on biased data without recognizing and addressing the bias, the system will reproduce and potentially amplify those patterns.
Article 10(2) of the EU AI Act specifically addresses this: for high-risk systems, training datasets must be subject to data governance practices that include examination for possible biases that could lead to discrimination. This requires proactive bias detection — testing datasets for representativeness across protected characteristics, measuring fairness metrics, and documenting the results. Remember the Amazon recruiting tool from Issue #003: it was trained on historical hiring data that reflected a decade of gender imbalance, and the system learned to penalize resumes that included indicators of being female.
Pillar 5: Security. AI data faces security threats that go beyond traditional data protection. Data poisoning — where an adversary deliberately corrupts training data to influence model behavior — is a well-documented attack vector. Access controls must ensure that only authorized processes can read, write, or modify training datasets. Integrity protections must detect unauthorized changes. And encryption must protect data both at rest and in transit, particularly when data moves between training environments, inference pipelines, and storage systems.
What To Do
Assess your current data governance against all five pillars — not just the ones you're comfortable with. Most organizations are strong on security and privacy (because GDPR and similar regulations forced them to be) but weak on lineage and bias detection. Those gaps are precisely where AI governance failures originate.
The AI Data Lifecycle: Where Governance Must Live
Data governance for AI isn't something you do once during data collection. It must be applied at every stage of the data lifecycle — from initial collection through model training, validation, production deployment, and eventual retirement.
 Collection. Governance begins the moment data enters your organization. You need a documented legal basis for collecting and using the data. Source information must be recorded — where did this data come from, when was it collected, under what terms? And the intended purpose must be defined: what AI use cases is this data being collected for?
Collection. Governance begins the moment data enters your organization. You need a documented legal basis for collecting and using the data. Source information must be recorded — where did this data come from, when was it collected, under what terms? And the intended purpose must be defined: what AI use cases is this data being collected for?
Preparation. Raw data rarely enters an AI model directly. It goes through cleaning, transformation, labeling, and annotation — each of which can introduce errors or bias. Data governance at this stage means validating that cleaning processes don't inadvertently remove important signal, that labels are consistent and accurate, and that the resulting dataset is representative of the population the AI system will serve.
Training. When data is used to train a model, the governance requirements include dataset versioning (which exact dataset was used for this training run?), train-test-validation split documentation (how was the data divided, and is each split representative?), and provenance tracking (can you connect the trained model back to the specific data that created it?).
Validation. Before deployment, AI systems must be tested — and the data used for testing is itself a governance concern. Validation datasets must be independent of training data. Performance must be measured across different demographic groups to detect disparate impact. Edge cases must be specifically tested. This is where the fairness testing required by the EU AI Act's Article 10 takes operational form.
Production. Once deployed, the data flowing into an AI system for inference must be monitored continuously. Input data that differs significantly from training data (data drift) can cause model performance to degrade. Logging of inputs and outputs creates the audit trail required by Article 12 of the EU AI Act. And the drift monitoring we discussed in Issue #004 — detecting when model behavior changes over time — depends entirely on having clean, well-governed production data.
Retention. Data doesn't last forever, and neither should it. Governance must define how long training data, model artifacts, and production logs are retained. Privacy regulations may require deletion after specific periods. Audit requirements may mandate retention for others. The retention policy must balance these competing demands and be consistently enforced.
The Regulatory Requirements: What the Law Actually Demands
Data governance for AI isn't just good practice — it's increasingly a legal obligation. Here's how the major regulations address it:
EU AI Act, Article 10 requires that training, validation, and testing datasets for high-risk AI systems are subject to appropriate data governance and management practices. Specifically: datasets must be relevant, sufficiently representative, and to the best extent possible free of errors and complete; datasets must take into account the specific geographical, contextual, behavioral, or functional setting in which the system is intended to be used; and for bias detection, providers may process special categories of personal data (race, ethnicity, gender, etc.) strictly for the purpose of ensuring bias monitoring, detection, and correction.
ISO 42001 addresses data governance through its requirements for the AI system lifecycle and its Annex B controls. The standard requires organizations to establish processes for data management that ensure the quality, integrity, and suitability of data used in AI systems. The AI system impact assessment — which we covered in depth in Issue #004 — must consider how data characteristics affect the system's impact on individuals and society.
GDPR applies whenever AI systems process personal data of EU residents. The principles of lawfulness, purpose limitation, data minimization, accuracy, storage limitation, and security all apply to AI training data. The right to explanation under GDPR's automated decision-making provisions (Article 22) is directly connected to data lineage — you can't explain a decision if you can't trace what data informed it.
Key Insight
The EU AI Act's Article 10 creates a unique tension: to detect bias, you may need to process sensitive personal data (race, gender, disability) — data that GDPR normally restricts heavily. The Act provides a specific exemption for this purpose, but it comes with strict conditions: the processing must be necessary for bias detection, and it must be protected by appropriate safeguards. Navigating this intersection requires close collaboration between your AI governance and privacy teams.
Third-Party Data: The Blind Spot
Many AI systems rely on data from third-party sources — purchased datasets, open-source training corpora, vendor-provided models, or data accessed through APIs. This introduces a governance blind spot that most organizations underestimate.
When you use third-party data to train or fine-tune an AI model, you inherit whatever governance gaps exist in that data. If the source dataset contains biased samples, your model inherits the bias. If the data was collected without appropriate consent, you inherit the privacy liability. If the dataset includes copyrighted material, you inherit the intellectual property risk.
Vendor due diligence for AI data requires several steps: understanding how the data was collected and whether appropriate consents were obtained, evaluating the representativeness and quality of the dataset, assessing whether the licensing terms permit your intended use (particularly for AI training), and documenting the provenance chain so you can demonstrate compliance if audited.
This connects directly to the third-party AI risk management we'll cover in more depth in a future issue. For now, the principle is simple: you are accountable for the data your AI systems use, regardless of where that data comes from.
Building Your AI Data Governance Program
Here's a practical framework for establishing AI data governance in your organization:
Step 1: Audit what you have. For every AI system in your inventory (you do have an inventory, right?), document what data it uses, where that data comes from, how it was collected, what transformations were applied, and when it was last validated. This audit alone will surface governance gaps you didn't know existed.
Step 2: Define ownership. Every dataset used in AI systems needs a clear owner — someone accountable for its quality, compliance, and lifecycle management. This is often a data steward or data product owner. Without ownership, governance becomes everyone's responsibility and therefore nobody's.
Step 3: Establish quality standards. Define what "good enough" looks like for each type of data. Not all data needs the same level of quality governance — a recommendation engine's training data and a credit scoring model's training data have very different quality requirements. Proportionality matters.
Step 4: Implement lineage tracking. Choose a level of lineage granularity appropriate to your risk profile. High-risk AI systems need detailed, field-level lineage. Lower-risk systems may need only dataset-level provenance. The goal is traceability — can you answer the question "what data informed this AI decision?"
Step 5: Integrate bias testing into your data pipeline. Don't wait until a model is in production to discover bias. Test datasets for representativeness before they're used for training. Measure demographic parity across protected characteristics. Document the results and any mitigation actions taken. This becomes your evidence of compliance with Article 10(2) of the EU AI Act.
What To Do
Start with Step 1 — the data audit. Pick your three highest-risk AI systems and document everything about their data. You'll find gaps you didn't expect: datasets without clear sources, transformations without documentation, personal data without verified consent. Each gap is a governance risk, and knowing about them is the first step to addressing them.
The GenAI Challenge: When You Don't Control the Training Data
Generative AI introduces a data governance challenge that traditional ML didn't have: organizations deploying foundation models (GPT-4, Claude, Gemini, Llama, etc.) typically have no visibility into the training data. You're using a model trained on data you didn't curate, can't inspect, and can't modify.
This doesn't exempt you from data governance — it shifts the focus. For GenAI deployments, governance should concentrate on the data you feed into the system (prompts, context, RAG documents), the outputs the system produces (accuracy verification, bias detection, hallucination monitoring), and the fine-tuning data if you customize models (which brings you back to full data governance responsibility). You also need clear contractual provisions with your model provider about how your data is used — whether inputs are used for model training, how data is stored and deleted, and what jurisdictions the data flows through.
The Connection to Everything Else
Data governance is not a standalone program. It connects to every other governance capability we've discussed in this newsletter. Your AI system inventory (Issue #001) must include data dependencies. Your risk taxonomy (Issue #003) must include data quality and bias risks. Your ISO 42001 management system (Issue #004) requires data governance as a foundational control. Your EU AI Act compliance (Issue #007) depends on meeting Article 10's data requirements. Even Shadow AI (Issue #005) is partly a data governance problem — when employees use unauthorized AI tools, the biggest risk is often the data they feed into those tools.
This interconnection is why data governance can't be delegated to a data team working in isolation. It must be integrated with your broader AI governance program, with clear connections between data stewards, AI risk managers, privacy professionals, and the business teams deploying AI systems.
Next Issue
Issue #009: Explainability in Practice — Making AI Decisions Understandable. One of the hardest responsible AI objectives to operationalize. We explore what explainability actually means for different stakeholders, the techniques available, and how to build explainability into AI systems from design — not as an afterthought.